TERAMOS |
TERAMOS |
Od roku 2010 vyvíjíme sadu speciálních, velmi výkonných, robustních a unikátně přesných algoritmů pro analýzu a porovnávání audio záznamů. Umožňují nám prohledávat a zpracovávat souběžně obrovské množství audio záznamů a vyhledávat v nich unikátní výskyty předem definovaných vzorů.
Pro každou specifickou typologii požadavku máme k dispozici odlišné algoritmy. Systém umožňuje rozsáhlou volbu parametrů pro každou metodu se záměrem navýšení přesnosti, rychlosti, nebo snížení paměťové náročnosti.
Celé řešení je vytvářeno v programovacím jazyce C s využitím Assembleru a specializovaných SSE a AVX instrukcí, proto dosahuje opravdu úctyhodné rychlosti.
Řešení umožňuje hledání shod krátkých úseků v záznamech (od jedné sekundy), ale i delších bloků (jako například hudebních útvarů).
Následující příklady dokládají robustnost algoritmů našeho audiomatchingu. První z nich je spektrogram originálního souboru pořízeného z rozhlasového vysílání ČRo 1: original.mp3, recorded.mp3
Jak je patrné z poslechu i ze spektrálních grafů pořízená nahrávka (druhý soubor) je velmi těžko rozeznatelná kvůli zarušení hlukem motoru (dlouhá rovná čára na spektrogramu) a také kvůli dalším zdrojům rušení, nicméně i přes tyto velmi špatné podmínky, kvůli nimž je záznam na samé hranici subjektivní rozpoznatelnosti, je audiomatching způsobilý najít podobu v hodnotách vyšších než 95%, což je i zřejmé na časovém průniku obou nahrávek.
Spektrogram hledaného vzorku audio úseku: 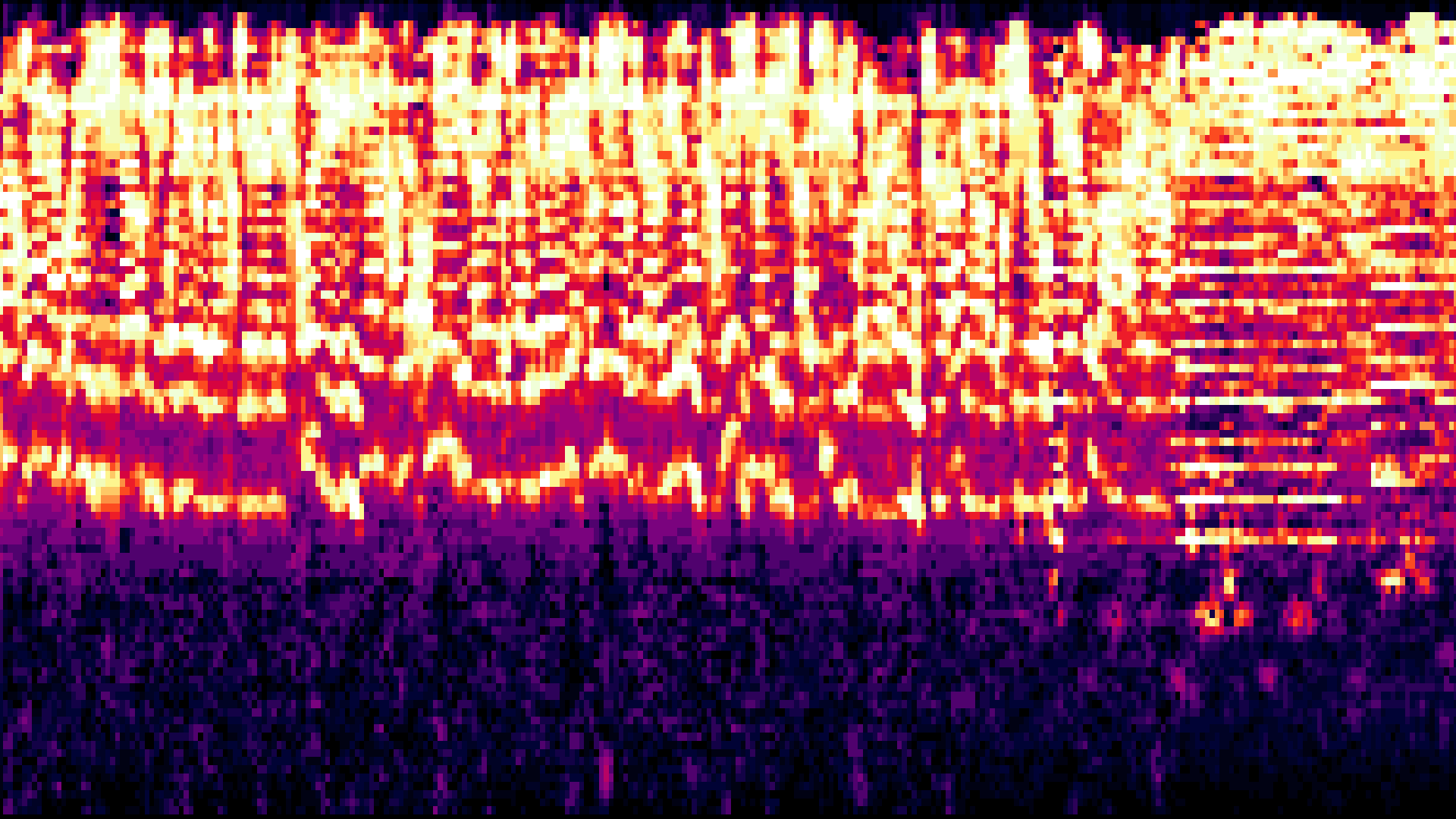
Spektrogram pořízeného záznamu: 
Optimální nalezený průnik s hledaným vzorem: 